
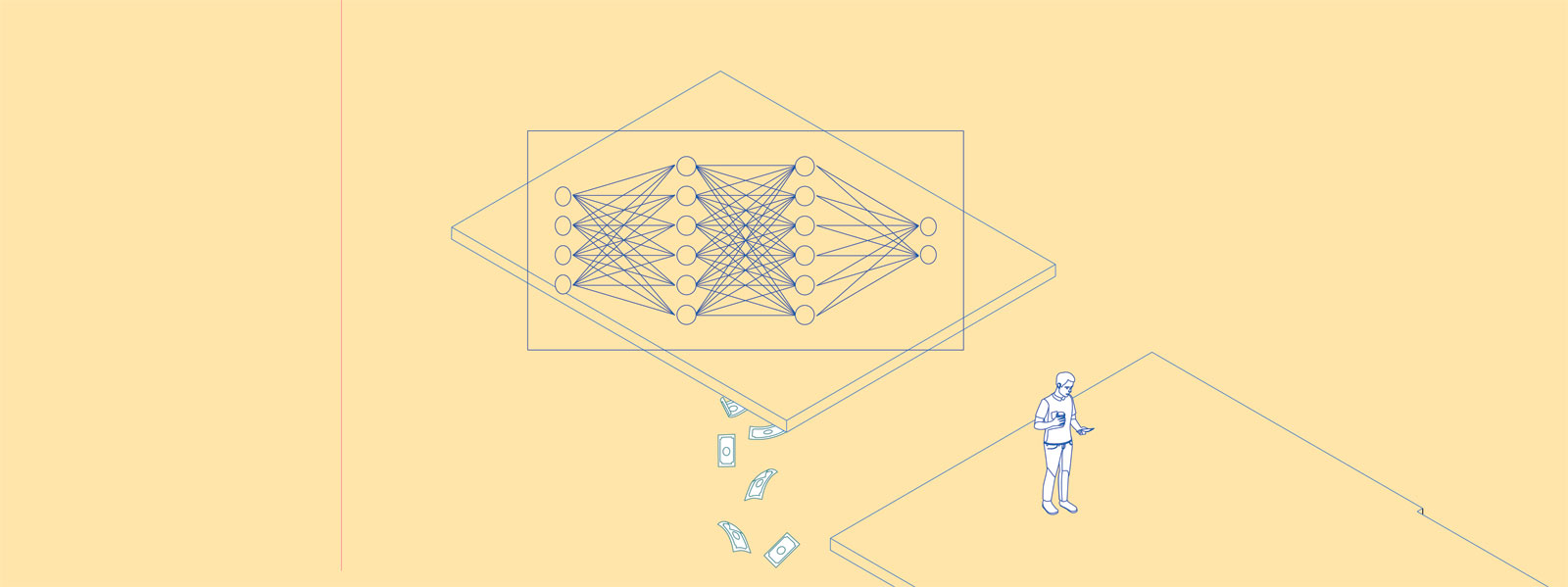
La popularización de la inteligencia artificial (IA) ha dado lugar a imaginarios que promueven la alienación y la mistificación. Ahora que estas tecnologías parecen consolidarse, resulta pertinente realizar la cartografía de sus vínculos con actividades y territorios que no son solo humanos. ¿Qué conjunto de extracciones, agencias y recursos nos permiten conversar en línea con una herramienta generadora de textos u obtener imágenes en segundos?
01. Las herramientas de IA generativa se utilizan para automatizar tareas como la escritura o la generación de imágenes. Esta automatización no resulta de la programación de pasos concretos por realizar, sino empleando ejemplos. Si tenemos muchos ejemplos de un caso, se pueden procesar utilizando redes estadísticas que se configuran analizando sus patrones recurrentes. Ya sean palabras, pixeles o frecuencias de sonido, es posible obtener un modelo estadístico analizando y explorando un conjunto de datos de entrenamiento. Diríamos que las herramientas de la IA generativa desmontan el lenguaje (visual, textual) para reensamblarlo basándose en un cálculo de probabilidades. Hasta hace unos años se entrenaba a estas herramientas para generar expresiones concretas (la imagen de un rostro, un texto con un estilo determinado); ahora van más allá de la concreción específica para producir distintos tipos y estilos de contenido. Esta capacidad de generalización se debe al procesamiento de conjuntos de datos mucho más amplios y heterogéneos que permiten responder a todo tipo de instrucciones. En consecuencia, la escala del cambio en la IA generativa ha sido tan grande que exige el impulso de nuevas economías y una dependencia acelerada de los distintos ecosistemas.
02. Conjuntos de datos. La compilación a escala industrial de conjuntos de datos de entrenamiento se consigue extrayendo contenidos del mayor archivo digital que existe: Internet. Los datos se obtienen mediante el scraping automatizado de contenidos publicados en línea y compartidos por millones de internautas. En un principio, lo que motivaba esta extracción no era la actual explotación comercial por parte de las empresas emergentes y las plataformas, sino el deseo de realizar investigaciones académicas y no comerciales. Ahora que estos enormes archivos digitales se utilizan para generar textos e imágenes a pedido, enfrentamos una serie de paradojas y controversias en el marco de las industrias culturales. Por un lado, la ideología del big data concibe a los contenidos de Internet como un inmenso archivo que puede ser explotado, procesado y automatizado. Pero este impulso extractivista es visto por otros actores culturales como un proceso de privatización masiva de la creatividad de millones de internautas.
03. Modelos de imitación estadística. Las industrias culturales han producido un gran porcentaje de las imágenes, los textos y los sonidos que alimentan los modelos de IA; a su vez, son sus usuarios principales y potenciales. El trabajo de fotógrafos, diseñadores, ilustradores, músicos, compositores, guionistas, escritores, desarrolladores, animadores y cineastas se emplea para entrenar estos modelos de imitación estadística. Aunque actualmente la estética de los contenidos generados no difiere mucho de la que caracteriza a los bancos de imágenes, fotos o sonidos, la velocidad a la que operan estos servicios automatizados difícilmente podrá ser igualada por ningún competidor humano. Por este motivo, los empleos más precarios de la producción cultural serán los más desfavorecidos y los más dependientes de la IA generativa.
04. Puesta a punto. Los conjuntos de datos son la materia prima; sin embargo, no bastan para alcanzar el nivel actual de interacción personalizada que ofrecen los servicios en línea de IA. Se necesitan equipos de personas dedicadas a realizar microtrabajos para refinar el modelo, como calificar las respuestas que genera, etiquetar imágenes o textos, realizar anotaciones y demás procesos de evaluación que implican trabajo cognitivo (con frecuencia solo implica hacer clic en una de las opciones que aparecen en pantalla). Las grandes corporaciones subcontratan estos servicios a otras empresas, que a su vez los exportan a países del sur global con altos índices de pobreza, donde el costo por hora del trabajo es un gasto marginal. Se ha documentado que algunas de las empresas subcontratadas operan en campos de refugiados en Líbano, Uganda, Kenia e India, donde entrenan a las personas desplazadas en realizar microtareas con datos, y así se aprovechan de sus adversidades económicas.1
05. Filtrado. En una fase más avanzada del proceso, es necesario filtrar el contenido generado por los grandes modelos de IA. Las tareas más comunes en esta etapa son las destinadas a moderar los denominados contenidos tóxicos —discursos de odio, controversias políticas, sexo y violencia extrema o explícita—, incluidos originalmente en los datos de entrenamiento. El trabajo de moderación se lleva a cabo en países como Kenia o Uganda (o incluso entre las comunidades de inmigrantes en las grandes metrópolis del norte) y consiste en identificar y clasificar textos e imágenes con contenido violento, asesinatos, violaciones o abuso de menores. Detrás de la aparente autonomía de las herramientas de IA, por tanto, existen diferentes capas de recursos humanos desplazados a diferentes geografías, precarizados e invisibilizados por la industria de la innovación tecnológica.
06. Las start-ups de IA. Este despliegue de recursos humanos desplazados depende en última instancia de las start-ups de IA generativa (OpenAI, DeepMind, Anthropic y otras), empresas alentadas por el valor fetiche de los modelos de IA y las renovadas oleadas de especulación tecnológica de Silicon Valley. Las start-ups de IA generativa se han consolidado en torno a la experiencia y la investigación especializada, pero también como actores globales que articulan estos micromercados laborales y se alían con las grandes plataformas para atraer capital financiero. Son las estrellas del actual frenesí en el mercado global de la innovación digital, compensan la desaceleración de la rentabilidad del capital de riesgo invertido en tecnología y cuentan con el conveniente estímulo de un discurso que centra el debate sobre la IA en el peligro que esta representa para la extinción de la humanidad.
07. Discursos públicos. El discurso del pánico alrededor de la IA, canalizado por institutos y fundaciones filantrópicas y secundado por los “visionarios” de las start-ups, recibe cobertura en los medios de comunicación y tiene el efecto deseado de alarmar a la opinión pública. En un momento en que estas tecnologías apenas se están sometiendo a los primeros procesos regulatorios (la primera ley sobre IA se aprobó en el Parlamento Europeo a principios de 2024), la agitación que provocan los mensajes pretende favorecer las exigencias de autorregulación de la industria de la IA ante las administraciones públicas. Mientras tanto, en el contexto de la crisis de los formatos estandarizados de credibilidad, definida desde hace algunos años con el término “posverdad”, las redes sociales ya se están llenando de mensajes, imágenes o textos sintéticos generados por estas herramientas. La automatización del discurso público y sus implicaciones en un contexto de creciente desinformación y polarización política estarán en el centro de la agenda mediática de los próximos años.
Seguir leyendo: Revista de la Universidad de México
